Differentiable Weights-Varying Nonlinear MPC via Gradient-based Policy Learning: An Autonomous Vehicle Guidance Example
Abstract
Tuning Model Predictive Control (MPC) cost weights for multiple, competing objectives is labor-intensive. Derivative-free automated methods, such as Bayesian Optimization, reduce manual effort but remain slow, while Differentiable MPC (Diff-MPC) exploits solver sensitivities for faster gradient-based tuning. However, existing Diff-MPC approaches learn a single global weight set, which may be suboptimal as operating conditions change. Conversely, black-box Reinforcement Learning Weights-Varying MPC (RL-WMPC) requires long training times and a lot of data. In this work, we introduce gradient-based policy learning for Differentiable Weights-Varying MPC (Diff-WMPC). By backpropagating solver-in-the-loop sensitivities through a lightweight policy that maps look-ahead observations to MPC weights, our Diff-WMPC yields rapid, sample-efficient adaptation at runtime. Extensive simulation on a full-scale racecar model demonstrates that Diff-WMPC outperforms state-of-the-art static-weight baselines and is competitive with weights-varying algorithms, while reducing training time from over an hour to under two minutes relative to RL-WMPC. The learned policy transfers zero-shot to unseen conditions and, with quick online fine-tuning, reaches environment-specific performance.
Contributions
- Gradient-based Policy Learning for Weights-Varying MPC: We introduce Differentiable Weights-Varying MPC (Diff-WMPC), which leverages solver-in-the-loop sensitivities to train a lightweight policy that adapts MPC weights based on look-ahead observations.
- Sample-Efficient Training: Our approach achieves competitive performance with state-of-the-art methods while reducing training time from over an hour (Reinforcement Learning Weights-Varying NMPC) to under two minutes, demonstrating significant improvements in computational efficiency.
- Zero-Shot Transfer and Online Adaptability: The learned policy transfers zero-shot to unseen conditions and can be quickly fine-tuned online to reach environment-specific performance, enabling robust deployment across varying scenarios.
Approach
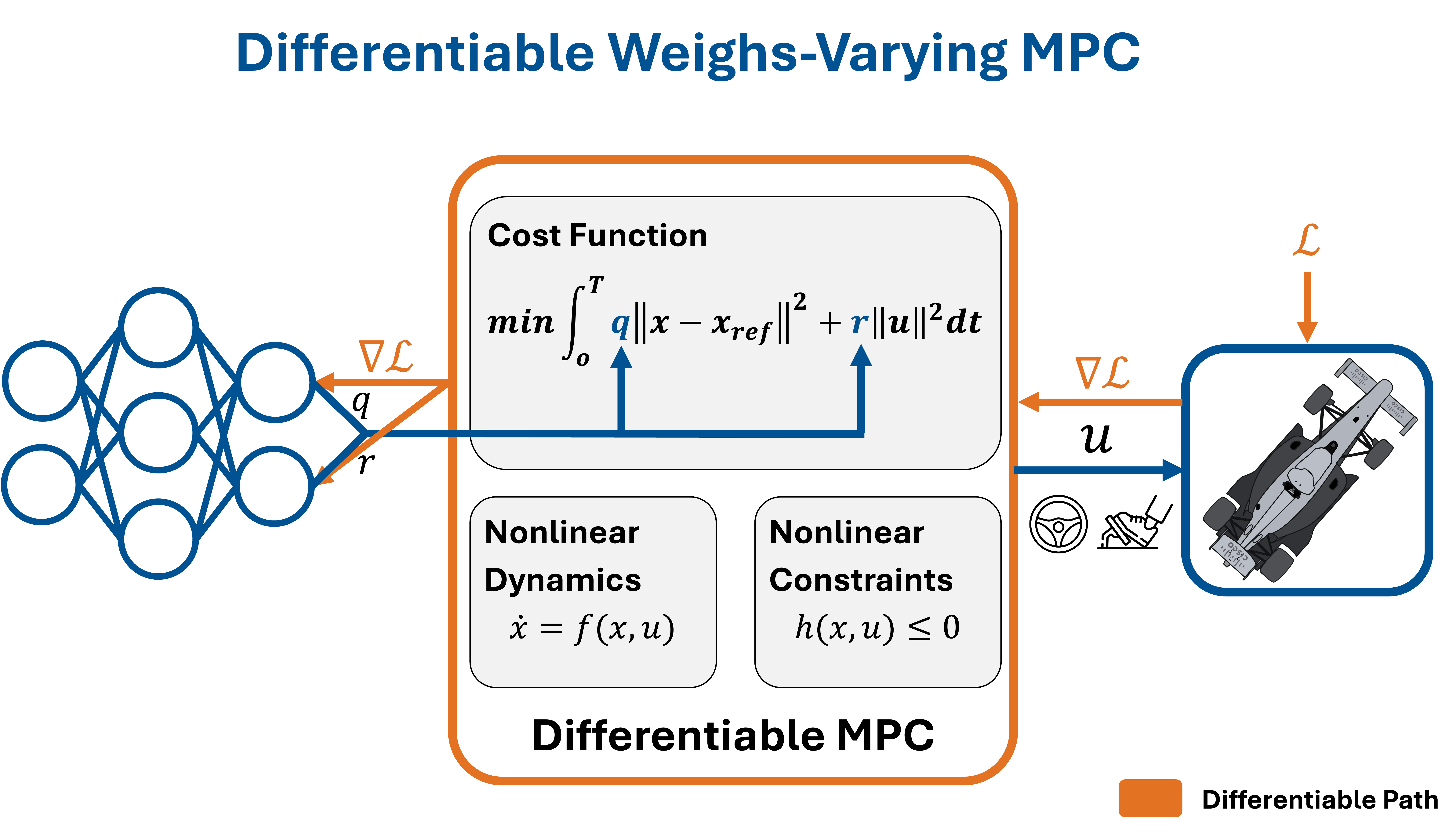
Our approach enables differentiable optimization for policy learning to enable adaptive, weights-varying Model Predictive Control. A lightweight neural network policy maps look-ahead observations to MPC cost weights (q and r), which parameterize the tracking and control effort trade-offs in the optimization problem. The MPC solver computes optimal controls u for the autonomous vehicle subject to nonlinear dynamics and constraints. By backpropagating gradients of a high-level task loss ℒ through the differentiable MPC solver, we efficiently train the policy to adapt weights based on upcoming trajectory conditions.
Results
Learning Control Policies in under Two Minutes
Diff-WMPC achieves over an order-of-magnitude speedup in both wall-clock time and sample efficiency compared to a reinforcement learning approach and superior performance relative to static-weight methods.
| Algorithm | Training Time [s] | Samples |
|---|---|---|
| MOBO-MPC Multi-Objective Bayesian Optimization MPC |
1071 | 460,278 |
| Diff-MPC (Ours) Differentiable MPC with Fixed Weights |
235 | 88,996 |
| RL-WMPC Reinforcement Learning Weights-varying MPC |
3885 | 1,000,000 |
| Diff-WMPC (Ours) Differentiable Weights-varying MPC |
101 | 36,778 |
Competitive Performance with State-of-the-Art Algorithms
Despite the drastically reduced training time, Diff-WMPC achieves competitive performance with weights-varying state-of-the-art algorithms on the Monza racetrack. The results demonstrate effective learning of the weights-varying policy and clear advantages over static-weight approaches.

Performance metrics comparing Diff-WMPC against baseline methods on the Monza racetrack.
Adaptive Weight Variation Around the Track
The learned policy dynamically adjusts MPC weights based on upcoming track features, balancing tracking accuracy and control effort as conditions vary around the circuit.
Demonstration of the adaptive control strategy.
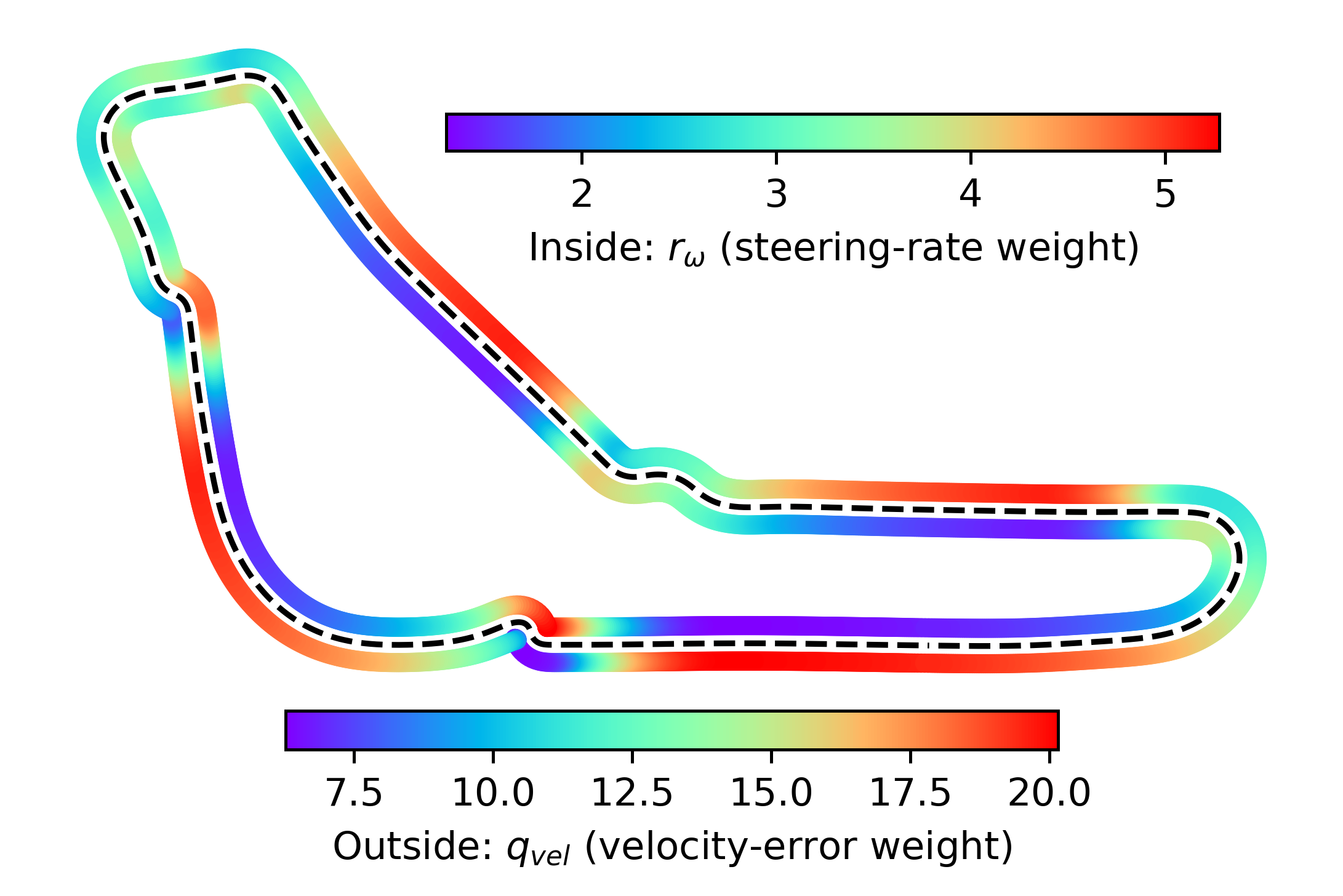
Weight adaptation visualization showing how the policy adjusts parameters around the race track.
Zero-Shot Transfer and Online Adaptation
To demonstrate robustness, we deploy the policy trained on Monza to an entirely unseen track (Laguna Seca) in zero-shot fashion, while introducing additional dynamical model mismatch. Quick online fine-tuning enables the policy to rapidly adapt to environment-specific characteristics.
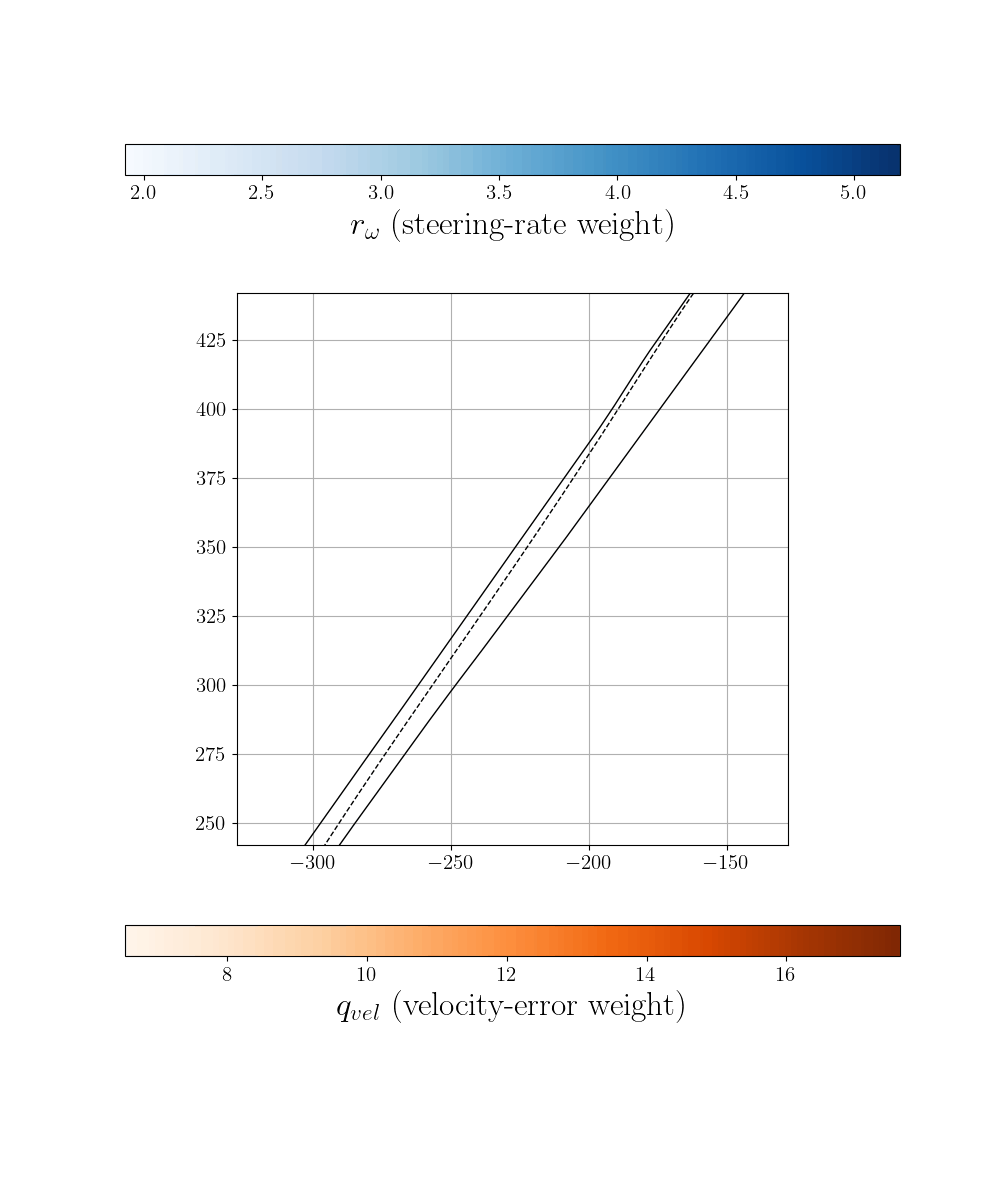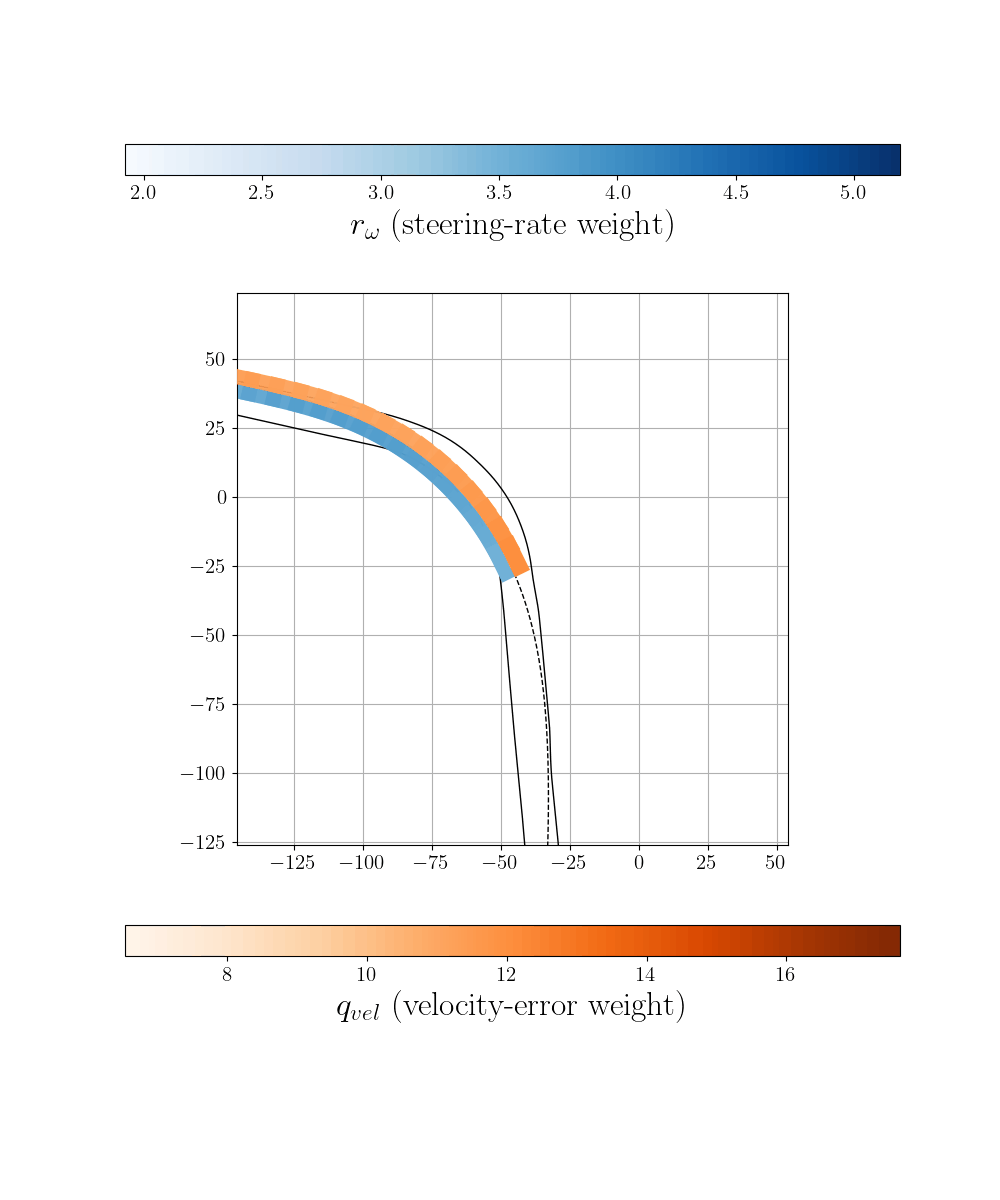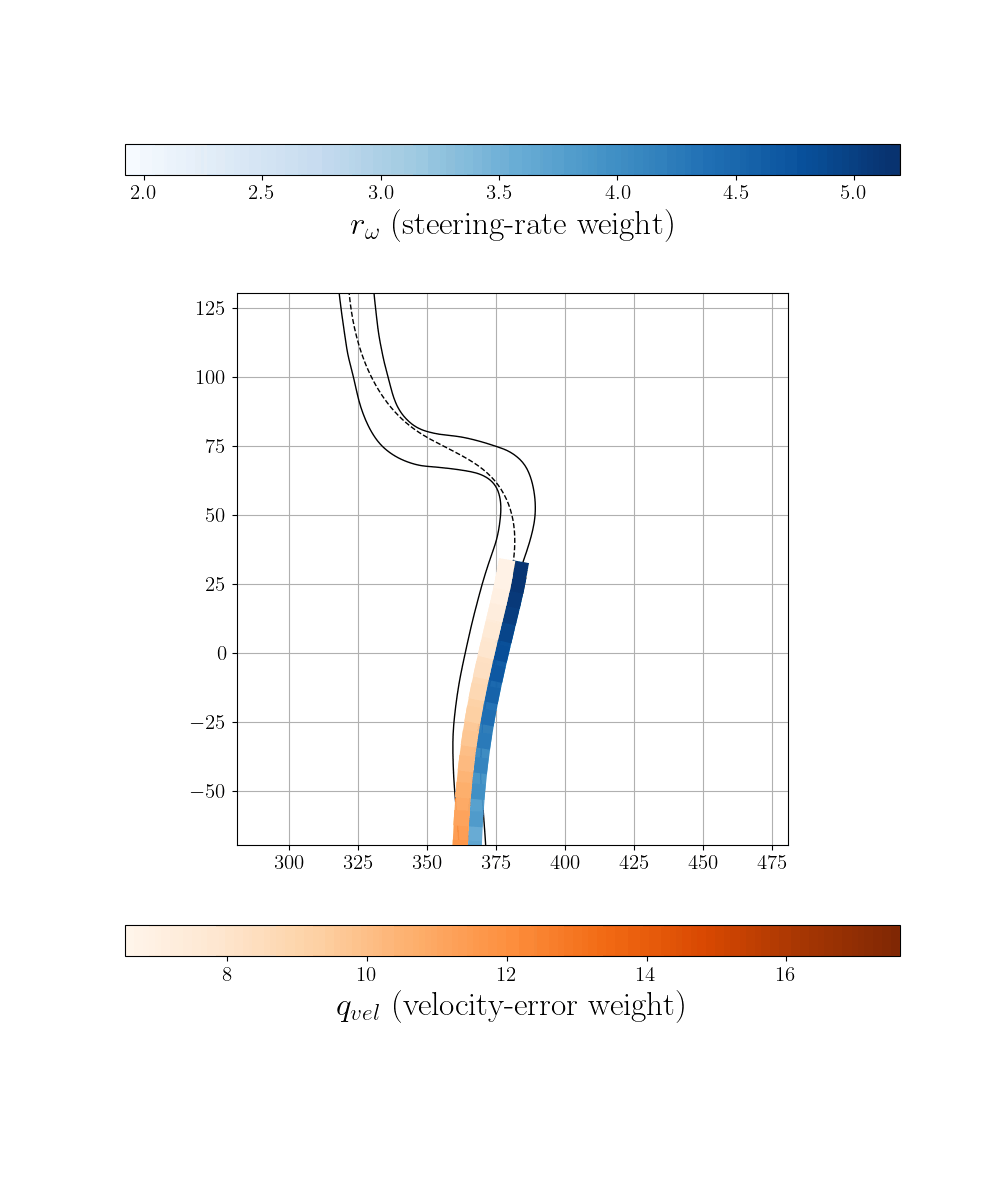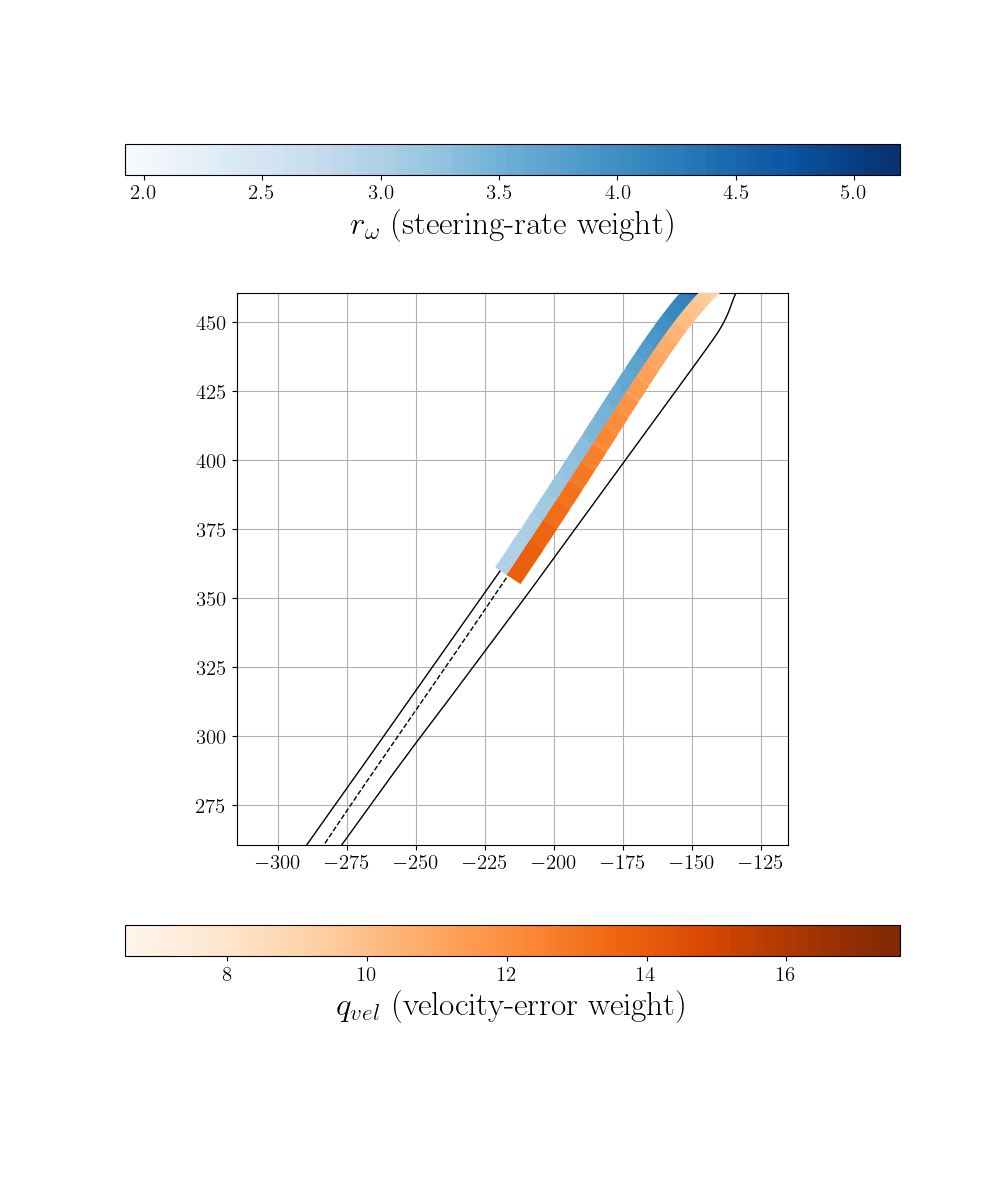
Adapted control on unseen Laguna Seca racetrack.
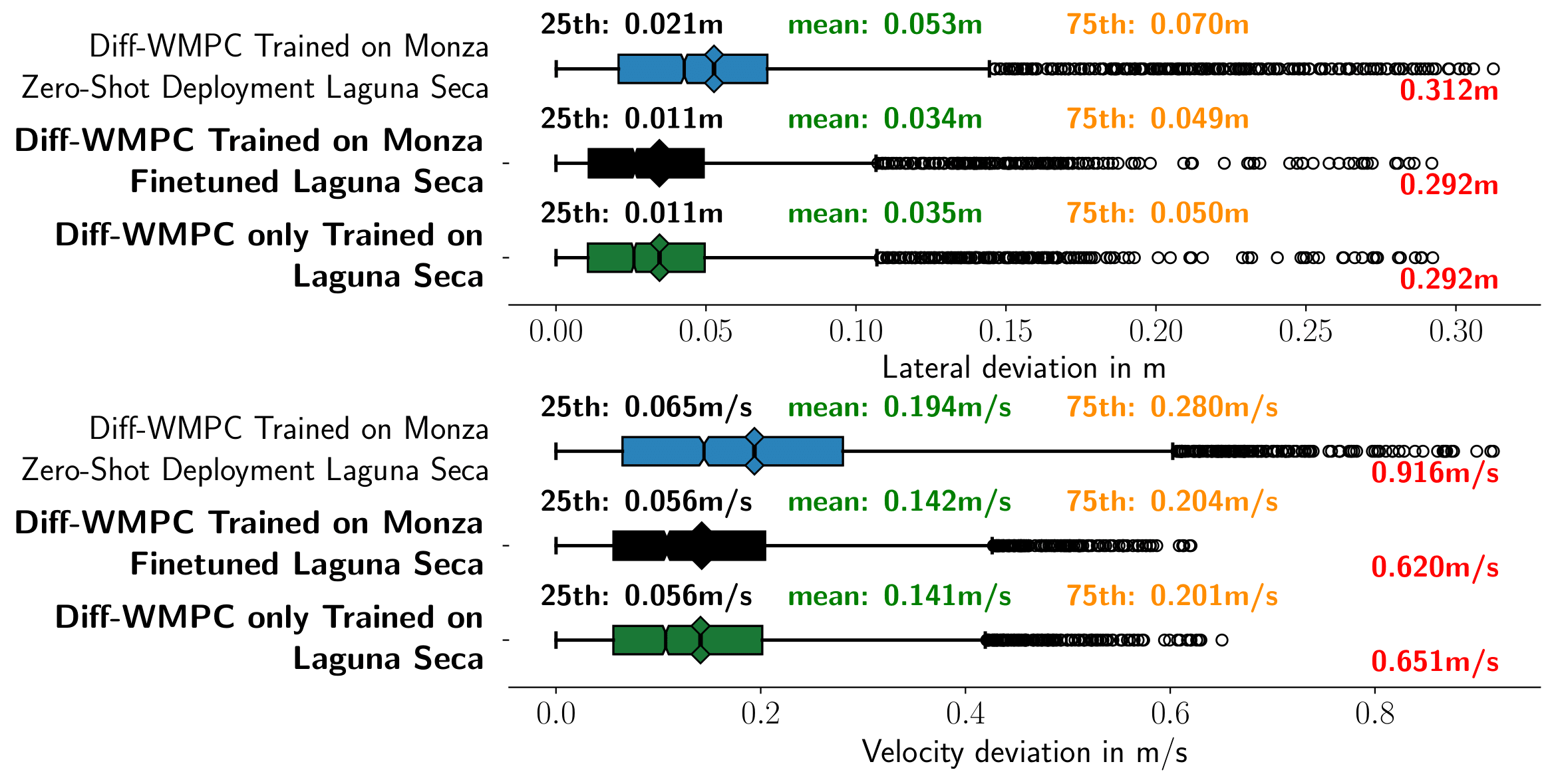
Performance on Laguna Seca circuit showing zero-shot transfer capability and improvements from online adaptation.
▶ Appendix A: Implementation Details
▶ Appendix B: Practical Stability and Feasibility
▶ Appendix C: Robustness to Initialization
BibTeX
@ARTICLE{11373898,
author={Jahncke, Felix and Zarrouki, Baha and Piccinini, Mattia and D'sa, Jovin and Isele, David and Bae, Sangjae and Betz, Johannes},
journal={IEEE Robotics and Automation Letters},
title={Differentiable Weights-Varying Nonlinear MPC via Gradient-based Policy Learning: An Autonomous Vehicle Guidance Example},
year={2026},
volume={11},
number={3},
pages={3724-3731},
keywords={Sensitivity;Costs;Vectors;Training;Cost function;Adaptation models;Predictive control;Tuning;Predictive models;Bayes methods;Machine learning for robot control;optimization and optimal control;differentiable MPC;weights-varying MPC},
doi={10.1109/LRA.2026.3662644}}
}